
General Guiding Principles (การออกแบบที่ดีและหลักการทั่วไป)
- Stop guessing your capacity needs: หยุดการคาดเดาเกี่ยวกับความจุ ควรใช้ตามความต้องการจริงของระบบ
- Test systems at production scale: ควรทดสอบประสิทธิภาพการ Scaling เพื่อช่วยให้มั่นใจได้ว่าระบบพร้อมเมื่อเผยแพร่ให้กับลูกค้า
- Automate to make architectural experimentation easier: ทำให้เป็นอัตโนมัติ เพื่อความง่ายในการทดสอบ เช่น CloudFormation, Beanstalk
- Allow for evolutionary architectures: ออกแบบสถาปัตยกรรมให้มีความสามารถในการวิวัฒนาการได้มากขึ้น
- Design bases on changing requirement: ออกแบบตามความต้องการที่เปลี่ยนแปลง เช่น เมื่อย้ายปริมาณงานจาก On-Premise ไปยังระบบคลาวด์ อาจจะทำเป็น Serverless เป็นต้น
- Drive architectures using data: ขับเคลื่อนสถาปัตยกรรมจากข้อมูลการใช้งานจริง
- Improve through game days: ปรับปรุงผ่านข้อมูลที่มีการใช้งานเยอะที่สุด เช่น
- Simulate applications for flash sale days: จำลองแอพพลิเคชันสำหรับวันที่มีแคมเปญ Flash Sale
AWS Cloud Best Practices – Design Principles (หลักการออกแบบเมื่อใช้คลาวด์และแนวทางปฏิบัติที่ดีที่สุด)
- Scalabitity: Vertical & Horizontal ต้องปรับขนาดได้ สามารถสร้างและลบเซิร์ฟเวอร์ได้อย่าง่ายดาย
- Disposable Resources: เซิร์ฟเวอร์ควรเป็นแบบใช้แล้วทิ้ง ดังนั้นต้องแน่ใจว่าได้สำรองข้อมูลแล้ว และต้องมีวิธีที่จะกำหนดค่าสถาปัตยกรรมใหม่ทั้งหมดได้อย่างรวดเร็ว
- Automation: ออกแบบให้เป็นระบบอัตโนมัติ เช่น Serverless, Infrastructure as a Service (IaaS), Auto Scailing เป็นต้น
- Loose Coupling: สร้างความยืดหยุ่นและประสิทธิภาพในระบบ เช่น แอพพลิเคชั่นที่ทำได้ทุกอย่าง และเมื่อเวลาผ่านไป ยิ่งเพิ่มเข้าไปในแอปพลิเคชันมากเท่าไหร่ก็ยิ่งมีขนาดใหญ่ขึ้นเท่านั้น จึงดูแลรักษายากและปรับขนาดได้ยาก ควรแยกมันออกเป็นส่วนประกอบที่ประกอบเล็กๆ เพื่อให้เชื่อมโยงกันผ่าน SNS หรือ SQS หรือด้วยวิธีอื่นๆ
- Services, not Server: ไม่ควรใช้ EC2 ทำทุกอย่างในแง่ของบริการ เช่น ใช้ RDS เป็นฐานข้อมูล, Serverless และอื่นๆ ที่สามารถทำให้ง่ายขึ้น
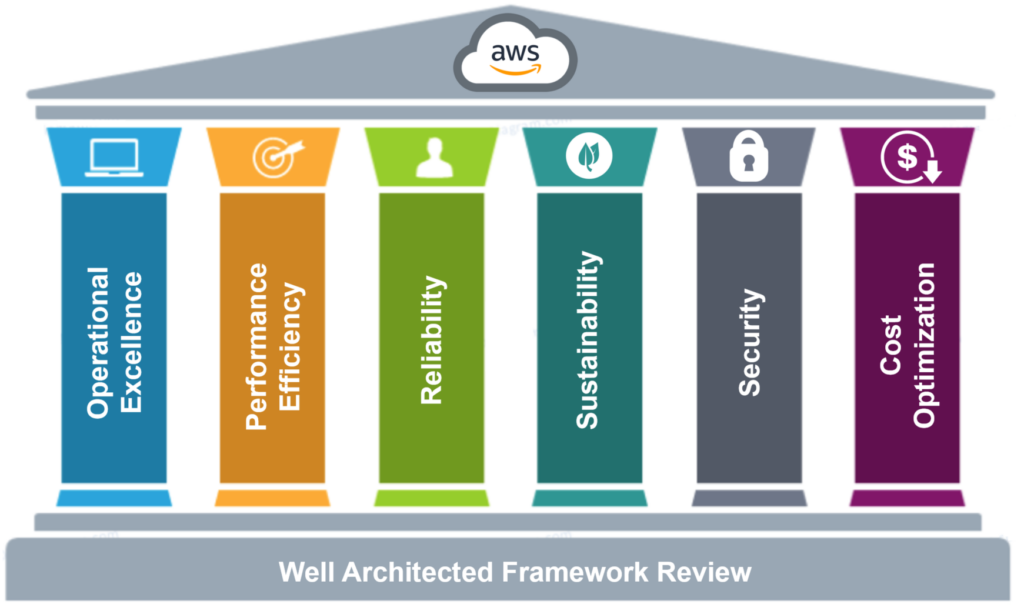
Well Architected Framework 6 Pillars (6 เสาหลักสำคัญในการออกแบบโครงสร้างที่ดี)

- Operational Excellence (การปฏิบัติงานที่มีประสิทธิภาพ)
- Security (ความปลอดภัย)
- Reliability (ความน่าเชื่อถือ)
- Performance Efficiency (ประสิทธิภาพในการทำงาน)
- Cost Optimization (การปรับค่าใช้จ่ายให้เหมาะสม)
- Sustainability (นวัตกรรมเพื่อความยั่งยืน)
1.Operational Excellence (การปฏิบัติงานที่มีประสิทธิภาพ)

- ความสามารถในการ Run และ Monitor ระบบ เพื่อสร้างมูลค่าทางธุรกิจ และปรับปรุงกระบวนการและขั้นตอนการสนับสนุนอย่างต่อเนื่อง
- Design Priciples: หลักการออกแบบ
- Perform operations as code: การใช้โครงสร้างพื้นฐานเป็นโค้ด ตัวอย่างเช่น ใน AWS นั่นจะเป็น AWS CloudFormation เป็นต้น
- Make frequent, small, reversible change: ตรวจสอบให้แน่ใจว่าได้ทำการเปลี่ยนแปลงเล็กๆ น้อยๆ แล้วเกิดข้อผิดพลาดใดๆ สามารถย้อนกลับได้ หากเริ่มทำการเปลี่ยนแปลงครั้งใหญ่ทุกๆ สามเดือน จะไม่เกิดปัญหา
- Refine operations procedures frequently: ปรับปรุงขั้นตอนการปฏิบัติงานบ่อยๆ และตรวจสอบให้แน่ใจว่าสมาชิกในทีมทุกคนคุ้นเคยกับขั้นตอนการปฏิบัติงานใหม่เหล่านี้
- Anticipate failure: คาดการณ์ความล้มเหลว
- Learn from all operational failures: กรณีที่ล้มเหลว คุณต้องเรียนรู้จากความล้มเหลวทั้งหมดนี้ ถ้าคุณไม่รับผลตอบรับจากความล้มเหลวของคุณ คุณก็จะไม่ดีขึ้นเลย
- Implement observability for actionable insights: ใช้บริการที่มีการจัดการเพื่อลดภาระในการปฏิบัติงานและใช้ความสามารถในการสังเกตสำหรับข้อมูลเชิงลึกที่ดำเนินการได้
2. Security (ความปลอดภัย)
- ความสามารถในการปกป้องข้อมูล ระบบ และสินทรัพย์ ในขณะที่มอบคุณค่าทางธุรกิจผ่านการประเมินความเสี่ยงและกลยุทธ์การลดความเสี่ยง
- Design Priciples: หลักการออกแบบ
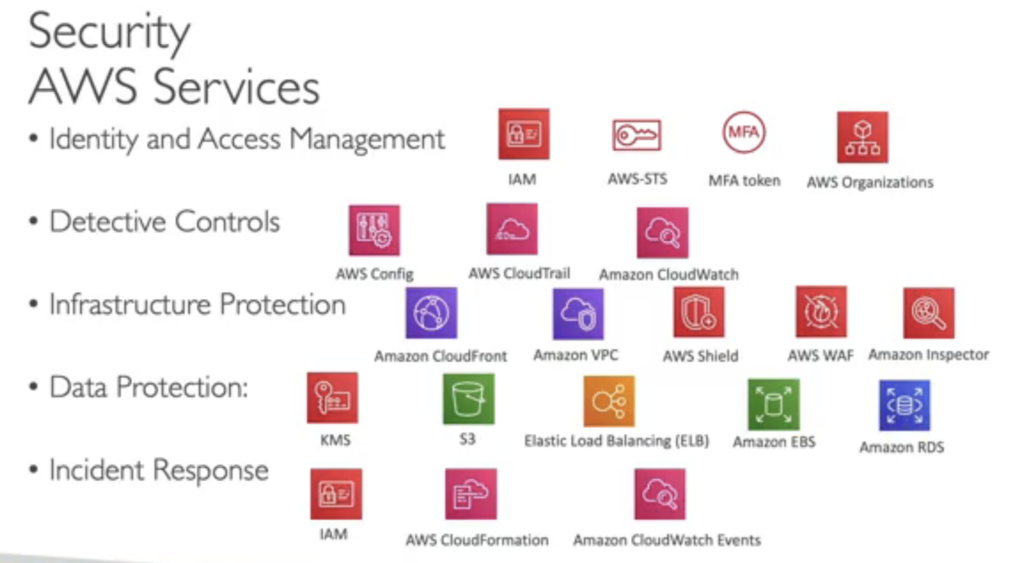
- Implement a strong identity foundation: เราจำเป็นต้องมีพื้นฐานตัวตนที่แข็งแกร่ง ดังนั้นเราจึงต้องการรวมศูนย์วิธีที่เราจัดการบัญชีผู้ใช้ เราต้องการ privilege ให้น้อยที่สุด และบางที IAM อาจเป็นหนึ่งในบริการเหล่านี้เพื่อช่วยเราทำเช่นนั้น
- Enable traceability: ต้องเปิดการใช้งานการตรวจสอบย้อนหลัง ซึ่งหมายความว่าเราต้องดูบันทึกทั้งหมด(Logs) เมตริกทั้งหมด จะต้องจัดเก็บไว้เป็นอัตโนมัติทุกครั้งที่มีบางสิ่งผิดปกติ
- Apply security at all layers: เช่น Edge Network, VPC, Subnet, Load balancer, Instance, OS, Patching และ Application ตรวจสอบให้แน่ใจว่าสิ่งเหล่านี้ปลอดภัยทั้งหมด
- Automate security best practices: ต้องทำทุกอย่างให้ปลอดภัยที่สุดเป็นไปโดยอัตโนมัติ
- Protect data in transit and at rest: เปิดใช้งาน Encryption, SSL, Token และ ควบคุมการเข้าถึงข้อมูลเสมอ
- Keep people away from data: ลดหรือจำกัดความจำเป็นในการเข้าถึงข้อมูลโดยตรง หรือ การประมวลผลด้วยตนเอง
- Prepare for security events: ต้องเตรียมความพร้อมสำหรับเหตุการณ์ด้านความปลอดภัย ตรวจสอบการจำลองด้านการตอบสนอง ใช้เครื่องมือเพื่อตรวจสอบความเร็ว และการกู้คืนต้องเป็นไปโดยอัตโนมัติ
3. Reliability (ความน่าเชื่อถือ)
- ความน่าเชื่อถือคือความสามารถของระบบในการกู้คืนจากโครงสร้างพื้นฐานหรือการหยุดชะงักของบริการ ดังนั้นจึงเป็นเรื่องของการทำให้แน่ใจว่าแอปพลิเคชันทำงานปกติ ไม่ว่าจะเกิดอะไรขึ้นก็ตาม
- Design Priciples: หลักการออกแบบ
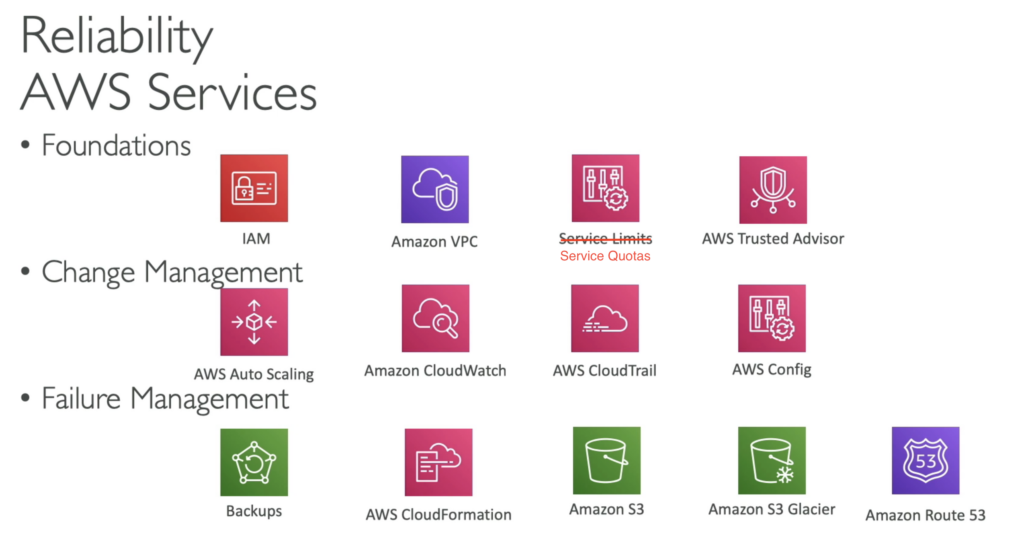
- Test recovery procedures: ต้องใช้ระบบอัตโนมัติเพื่อจำลองความล้มเหลวต่างๆ หรือสร้างสถานการณ์ที่นำไปสู่ความล้มเหลวก่อนหน้านี้อีกครั้ง
- Automatically recover from failure: กู้คืนจากความล้มเหลวโดยอัตโนมัติ ต้องคาดการณ์และแก้ไขความล้มเหลวก่อนที่จะเกิดขึ้น
- Scale horizontally to increase aggregate system availability: ปรับขนาดตามแนวนอนในกรณีที่ต้องการเพิ่มความพร้อมใช้งานของระบบหรือโหลดที่เพิ่มขึ้น
- Stop guessing capacity: หยุดการคาดเดาเกี่ยวกับความจุ ให้รักษาระดับที่เหมาะสมที่สุดเพื่อตอบสนองความต้องการโดยไม่ต้องจัดเตรียมมากเกินไปหรือน้อยเกินไป
- Manage change in automation: จำเป็นต้องเปลี่ยนแปลงทุกอย่างผ่านระบบอัตโนมัติ เพื่อให้แน่ใจว่าแอปพลิเคชันจะเชื่อถือได้ หรือสามารถย้อนกลับได้
4. Performance Efficiency (ประสิทธิภาพในการทำงาน)

- ความสามารถในการใช้ทรัพยากรการประมวลผลอย่างมีประสิทธิภาพเพื่อตอบสนองความต้องการของระบบ และเพื่อรักษาประสิทธิภาพดังกล่าวเมื่อความต้องการเปลี่ยนแปลงและเทคโนโลยีเปลี่ยนแปลงไป
- Design Priciples: หลักการออกแบบ
- Democratize advanced technology: ต้องใช้เทคโนโลยีขั้นสูง เมื่อบริการพร้อมใช้งาน บางทีอาจเป็นประโยชน์สำหรับการพัฒนาผลิตภัณฑ์
- Go global in minutes: ต้องสามารถเผยแพร่ไปทั่วโลกได้ภายในไม่กี่นาที หากต้องการปรับใช้ในหลายภูมิภาค ไม่ควรใช้เวลาหลายวัน แต่ควรใช้เวลาไม่กี่นาที
- Use serverless architectures: ใช้โครงสร้างพื้นฐานแบบไร้เซิร์ฟเวอร์ ไม่ต้องจัดการเซิร์ฟเวอร์ใดๆ และทุกอย่างจะปรับขนาดให้
- Experiment more often: ทดลองให้บ่อยขึ้น บางทีอาจมีบางอย่างที่ทำงานได้ดีในวันนี้ แต่คิดว่าอนาคตมันจะไม่เพิ่มขึ้นถึง 10 เท่าของโหลดหรือไม่
- Mechanical sympathy: ติดตามทุกอย่างของบริการ AWS เนื่องจากเมื่อมีการเปลี่ยนแปลงใหม่ๆ เกิดขึ้น การเปลี่ยนแปลงสถาปัตยกรรมโซลูชันอาจเปลี่ยนแปลงไปอย่างมาก
5. Cost Optimization (การปรับค่าใช้จ่ายให้เหมาะสม)
- ความเสถียรในการรันระบบ เพื่อมอบมูลค่าทางธุรกิจแต่ในราคาที่ต่ำที่สุดเท่าที่จะเป็นไปได้
- Design Priciples: หลักการออกแบบ
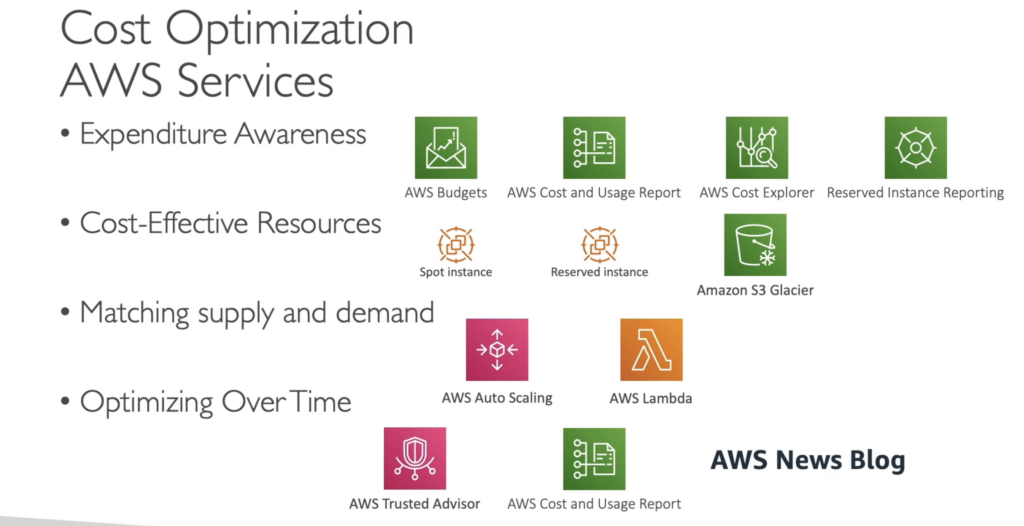
- Adopt a consumption mode: จ่ายเฉพาะสิ่งที่ใช้ เช่น AWS Lambda จะไม่ต้องเสียค่าใช้จ่าย หากไม่ได้ใช้งาน ในขณะที่ RDS หากไม่ได้ใช้ฐานข้อมูล ยังคงต้องจ่ายเพราะมีการจัดเตรียมฐานข้อมูลแล้ว
- Measure overall effciency: วัดประสิทธิภาพโดยรวม ใช้ CloudWatch ว่าใช้ทรัพยากรอย่างมีประสิทธิภาพหรือไม่?
- Stop spending money on data center operation: เช่น ค่าไฟ ค่าใช้งานเครือข่าย ค่าซ่อมบำรุง เป็นต้น หากย้ายไปที่ระบบคลาวด์ จะหยุดใช้เงินไปกับการดำเนินงานของศูนย์ข้อมูล เพราะ AWS จะทำโครงสร้างพื้นฐานให้ และมุ่งเน้นไปที่ระบบและแอปพลิเคชัน
- Analyze and attribute expenditure: ใช้ tags ในการติดตามค่าใช้จ่าย หากไม่ใช้ tags ในทรัพยากร AWS จะต้องมีปัญหามากมายในการหาว่าแอปพลิเคชันใดทำให้เสียเงินเป็นจำนวนมาก การใช้ tags ช่วยให้แน่ใจว่าสามารถติดตามค่าใช้จ่ายของแต่ละแอปพลิเคชันและเพิ่มประสิทธิภาพเมื่อเวลาผ่านไป
- Use managed and application level services to reduce cost of ownership: บริการที่ได้รับการจัดการทำงานบนระบบคลาวด์ สามารถเสนอต้นทุนต่อธุรกรรมหรือบริการที่ต่ำกว่าได้ เช่น Reserved Instances, Spot instances
6. Sustainability (นวัตกรรมเพื่อความยั่งยืน)

- การลดผลกระทบต่อสิ่งแวดล้อมจากการใช้งานปริมาณงานบนคลาวด์ให้น้อยที่สุด
- Design Priciples: หลักการออกแบบ
- Understand your impact: ต้องการเข้าใจผลกระทบ โดยการสร้างตัวชี้วัดประสิทธิภาพ และ ประเมินการปรับปรุง
- Establish sustainability goals: กำหนดเป้าหมายระยะยาวสำหรับแต่ละปริมาณงาน โมเดลผลตอบแทนจากการลงทุน(ROI: Return On Investment)
- Maximize utilization: ใช้ประโยชน์สูงสุดจากบริการ เพราะต้องการประหยัดพลังงานและใส่ใจสิ่งแวดล้อม
- Anticipate and adopt new, more efficient hardware and software offerings: ต้องการคาดการณ์และนำฮาร์ดแวร์ใหม่ที่มีประสิทธิภาพมากขึ้นมาใช้เมื่อเวลาผ่านไป เนื่องจาก AWS ทำการเพิ่มประสิทธิภาพบางอย่างให้กับโครงสร้างพื้นฐาน
- Use managed service: การย้ายข้อมูลที่เข้าถึงไม่บ่อยไปยัง Cold storage และการปรับ Compute capacity
- Reduce the downstream impact of your cloud workloads: ลดปริมาณการใช้พลังงานหรือทรัพยากรที่ไม่จำเป็นสำหรับการใช้บริการ
Credit:

Cool!
Thanks krub